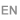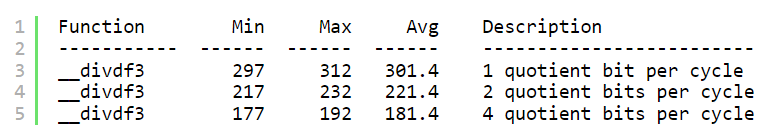SEGGER的运行时库和浮点库中提供了各种除法实现,然而,哪种算法是最好的(在代码大小、执行速度或能效方面),很大程度上取决于目标指令集架构(ISA)和ISA在芯片中实现的方式。
我们假设在具有以下特征的32位RISC-V内核上执行应用:
1、简单的算术和逻辑指令在一个周期内执行
2、内存加载总是命中cache并在一个周期内执行
3、分支永远不会被错误预测,并且无论是否执行,都在单个周期中执行
4、乘法指令在三个周期内完成
5、除法指令每周期提供1、2或4位商,具体数字由芯片设计者配置
有了这些,我们就可以对具有不同性能特征的除法指令进行基准测试。
基准框架
SEGGER有内部基准来确定emRun的性能,这些基准测试在Embedded Studio的模拟器上运行,并测量32位和64位除法算法的性能,使用分散输入来确保性能平摊。接下来将重点介绍在没有FPU的32位处理器上执行的64位浮点除法。
emRun为除法提供了多种配置,从clockwork的逐位算法到高速的乘倒数算法。
clockwork除法
如果没有硬件乘法器和硬件除法器,只能选择逐位除法,使用SEGGER Embedded Studio模拟器和emRun基准测试,性能如下:
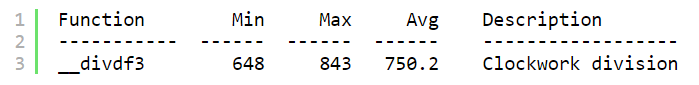
除了内部循环展开,使函数变得更大之外,没有其它优化方法。
使用M指令扩展
RISC-V M扩展提供32位乘法和除法指令,使用这些指令可以有效地实现64位除法。emRun根据内核配置方式提供了多种实现。
强制使用DIVU(无符号除法)和REMU(无符号余数)指令。53位除法(用于除双精度有效数)的一种实现是使用简单算法,每一步提供10或11位商,以及最后的舍入位。以这种方式使用DIVU和REMU会产生以下性能,具体取决于硬件除法器的实现:

通常,DIVU和REMU是顺序执行的。在没有融合的情况下,计算一个商和一个余数要花费两倍的时间,因为要进行两次除法,浪费了时间和精力。
与使用REMU指令计算余数相比,使用乘法器并手动计算余数要快得多。使用这种技术可以提高性能,但代价是每个除法步骤增加一条指令,所以总共有五条指令:
如果性能很重要,显然可以使用快速乘法器来计算除法后的余数。
使用Zmmul扩展
RISC-V Zmmul扩展只引入乘法指令。在Zmmul被批准之前,有一些设备以仅乘法器的配置交付。emRun为只有乘法器的内核提供快速除法,并且它的性能非常好:
以3周期乘法器为例,emRun平均可以在249.2个周期内实现两个双精度值除操作。使用16周期(每周期2位商)除法器,emRun平均可以在221.4个周期内实现两个双精度值除。两者的性能差异约为12.5%。在没有除法器的内核中,使用emRun可以实现每周期2位商除法器的性能。
整数除法
emRun也为整数运算提供了优化,但它还可以利用P扩展实现更快的乘法和除法以及更紧凑的代码。B扩展的多个变体以相同的方式部署,同样交付更快、更紧凑的代码。
emRun算法实现有通用C语言版本,并提供针对Arm和RISC-V架构优化的汇编语言版本。
对于RISC-V内核,除法不像乘法那样经常使用。由于除法可以使用乘倒数有效地完成,除非除法的速度很重要并且除法非常快(或者额外的硬件成本无关紧要),否则无需使用硬件除法器。
emRun是一个完整的C运行时库,可用于任何工具链。它将基于GCC/ LLVM的工具链转换为专业的开发选择。emRun已集成到Embedded Studio环境中,帮助用户生成高效、可靠的代码。
Embedded Studio基于一个IDE,即可实现ARM和RISC-V处理器应用,免费用于非商用应用。麦克泰技术提供Embedded Studio商业授权,具有丰富的软件开发与调试工具使用方面的知识和经验,欢迎咨询info@bmrtech.com。